Изкуственият интелект е здраво вкоренен в различни сфери на дейност, а науката не е изключение. Много учени активно го използват в процеса на написване на научни трудове. Именно затова преди публикуването научните списания внимателно проверяват статиите за наличие на следи от ИИ. Но дали тези детектори са наистина ефективни? Дават ли те стопроцентова гаранция за достоверността на резултатите? Днес ще поговорим за това по-подробно.

AI детектори: ефективни ли са те?
Спазването на принципите на академичната добродетел е в основата на научната дейност. Ето защо, преди да изпратят статия за рецензиране, научните списания я проверяват за възможни признаци на използване на изкуствен интелект. За тази цел съществуват специални инструменти, които анализират текста и предоставят доклад за уникалността му. В практиката обаче такива AI детектори не работят безупречно. Напротив, те имат много недостатъци, които могат да повлияят значително на обективността на резултатите. Как точно се проявяват те?
Недостатък 1: фалшиво положителни резултати поради академичния стил
Научните текстове по своята същност имат сходен стил на писане, тъй като в тях се използват утвърдени термини, типични конструкции на изреченията и неутрален тон. В процеса на анализ детекторите търсят именно тези признаци, по-специално повтарящи се езикови шаблони, формално изложение и ясна структура. Те са така наречените „маркери“, които трябва да свидетелстват, че авторът на текста не е човек, а инструмент на базата на изкуствен интелект.
В резултат възниква парадокс: автор, който владее добре научния стил, използва правилната терминология и спазва стандартите, автоматично попада под подозрение. Колкото по-добре е написана статията, толкова по-голяма е вероятността детекторът погрешно да я определи като текст, създаден от изкуствен интелект. В резултат на това той дава фалшиво положителни резултати и висок процент на използване на ИИ.
Недостатък 2: неразбиране на това как всъщност авторите използват технологиите на ИИ
В научната общност съществува мнение, че изследователите използват технологиите на изкуствения интелект изключително за генериране на пълния текст на статията. Всъщност обаче това е предубеждение, тъй като съвременните учени използват ИИ като помощник на различни етапи от работата си, например за генериране на идеи по време на мозъчна атака, за структуриране на големи количества данни, за преформулиране на сложни формулировки, за коригиране на граматиката в текстове на чужд език или за подобряване на четимостта на отделни абзаци. Това е целенасочено, съзнателно използване на инструмента, при което основните идеи, методология и заключения остават авторски.
Но детекторите не виждат тази разлика. За алгоритъма няма значение дали сте генерирали цялата статия с едно запитване или сте използвали езиковия модел само за подобряване на две изречения. Всяко използване на спомагателни технологии автоматично маркира статията като „написана от изкуствен интелект“, което не отговаря на действителността.
Недостатък 3: невъзможност да се оцени реалният принос на автора
Както отбелязахме по-горе, ИИ все по-често се явява като технически помощник, който помага на учените да изразят по-добре своите мисли, а не като заместител на човешкото мислене. Например, когато математик използва калкулатор за изчисления, това не означава, че той не е автор на изследването.
По същия начин използването на езикови модели за редактиране или форматиране на текст не отменя това, което авторът е вложил в работата си. Но детекторите не могат да оценят това. Те не правят разлика дали авторът сам е разработил методологията, провел експеримента, анализирал данните и направил изводите (използвайки ИИ само за техническо подобряване на текста), или просто е генерирал цялата статия автоматично. Тази ограниченост води до погрешни заключения за качеството и оригиналността на научната работа.
Недостатък 4: създаване на сериозни етични проблеми в академичната среда
Когато детекторите погрешно определят научни работи като създадени от изкуствен интелект, това поражда поредица от етични конфликти. Авторите могат да получат несправедливи обвинения в нарушение на академичната добродетел, въпреки че всъщност са работили честно върху своето изследване. Това подкопава доверието между учените и редакциите на списанията, а също така може да нанесе щети на научната репутация на изследователите.
Особено уязвими стават младите учени или тези, които публикуват на чужд език, тъй като техните текстове по-често попадат под подозрение поради по-малко естествения език или опитите да се усъвършенства стилът с помощта на технологии. Освен това, фалшивите обвинения могат да доведат до отхвърляне на качествени изследвания, забавяне на публикации и загуба на възможности за кариерно развитие. Определянето на истинското авторство изисква много по-задълбочен анализ, отколкото автоматичната проверка с програма.
Примери за грешки в работата на AI детекторите
За да разберем как се проявява нестабилността на AI детекторите на практика, нека разгледаме три реални случая.
Практически случай 1: влошаване на резултатите след редакции
В този случай авторите на научна статия се сблъскаха със ситуация, която ясно демонстрира ненадеждността на AI детекторите. Първоначалната проверка на статията от списанието показа резултат от 28% вероятност за използване на изкуствен интелект. Редакцията поиска този показател да бъде намален до 20% и предостави подробен доклад, в който конкретни фрагменти от текста бяха маркирани като „AI-like“.
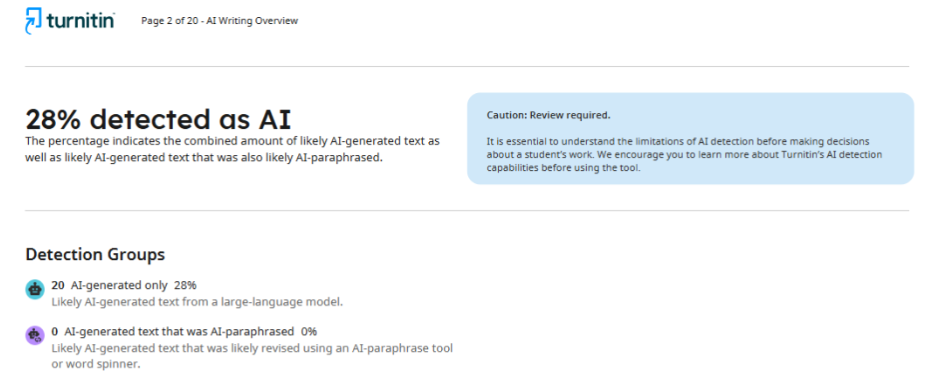
Авторите пренаписаха само онези фрагменти, които детекторът определи като проблемни, без да засягат останалата част от текста. След повторна проверка обаче същото списание предостави доклад с резултат 89%. Всъщност показателят се е увеличил повече от три пъти, вместо да се понижи, както се очакваше.
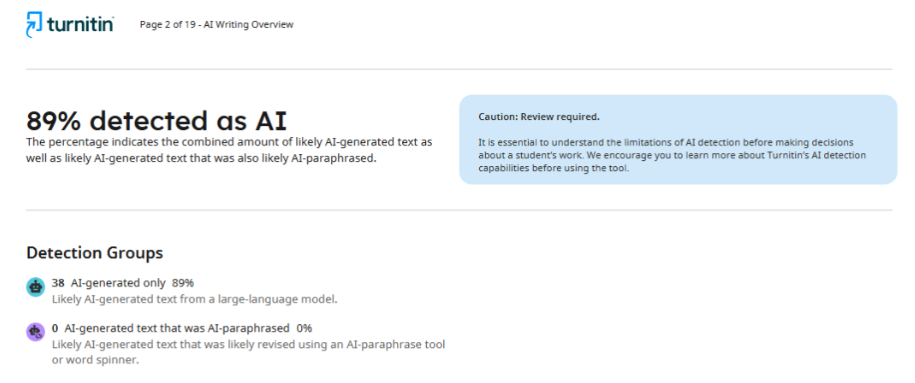
Тази ситуация разкрива един от ключовите проблеми на AI-детекторите: те нямат стабилни критерии за оценка и дават непредсказуеми резултати дори след корекции.
Практически случай 2: различни резултати за един и същ текст
Още по-показателен е случаят, когато една и съща версия на статията, проверена от една и съща система, но в различни списания, получи значително различни резултати. В първото научно издание системата показа 49% използване на изкуствен интелект.
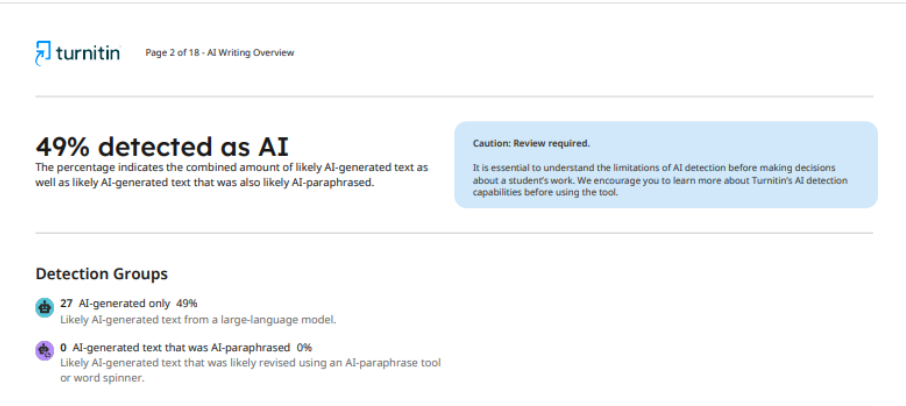
Що се отнася до второто списание, след проверка на статията то предостави на автора доклад, в който беше посочено 62% използване на ИИ. Тази непоследователност в резултатите показва, че детекторите не могат да осигурят стабилна и точна оценка, а способността им да определят дали са използвани технологии за изкуствен интелект в процеса на писане остава под въпрос.
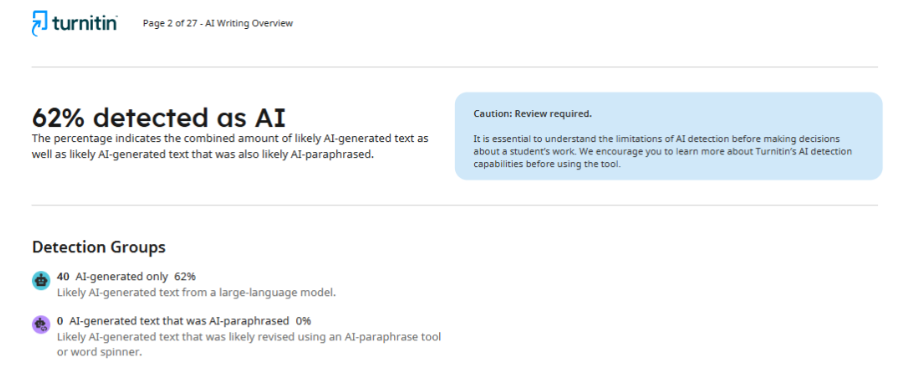
Практически случай 3: разлика в резултатите на различни програми
Струва си да се отбележи, че не съществува универсална програма, която да се използва от всички научни списания. Всяко научно издание самостоятелно избира инструменти за проверка на статиите за наличие на следи от изкуствен интелект. Именно този аспект оказва съществено влияние върху обективността на резултатите.
Например, в този случай за анализа на една статия са използвани два различни детектора: Turnitin и Pangram. В доклада, предоставен от първата платформа, е посочено, че 45% от текста е генериран от изкуствен интелект.
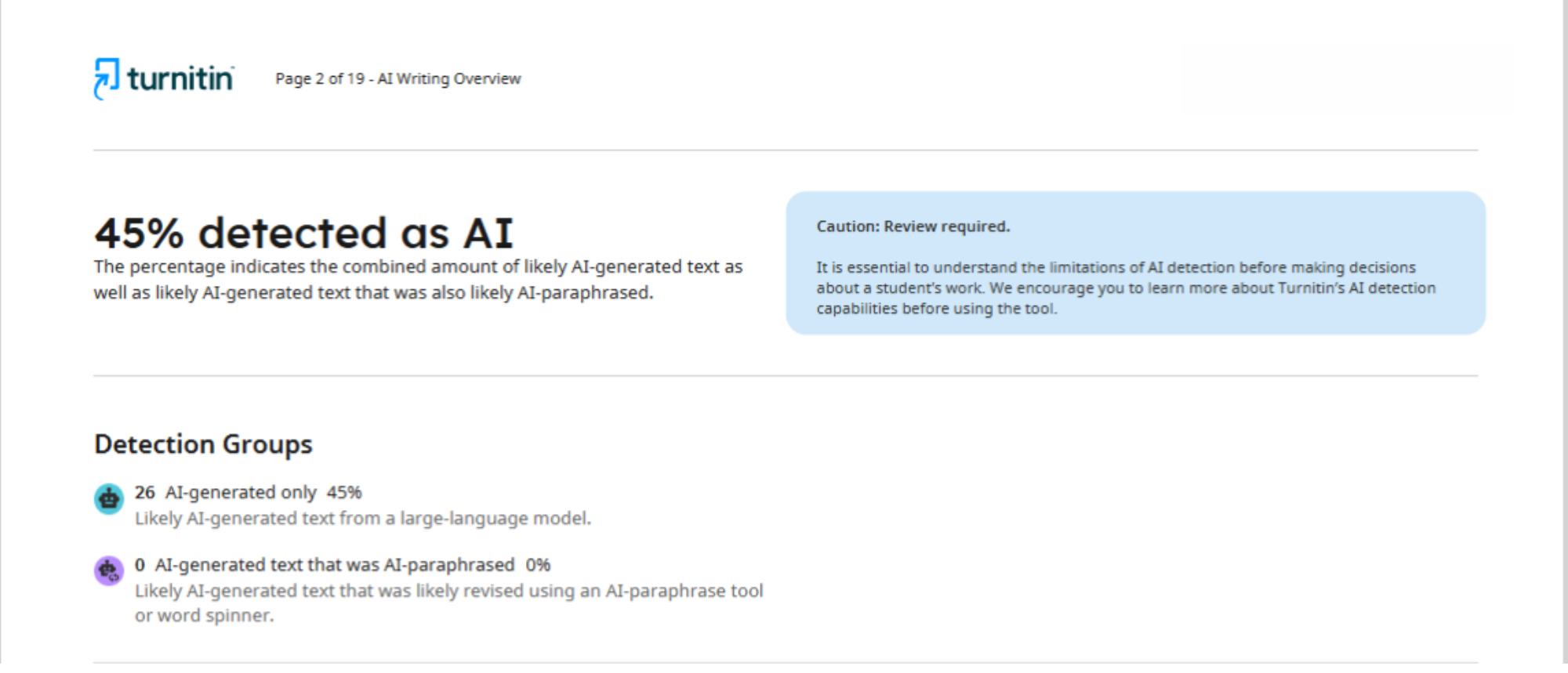
Що се отнася до Pangram, той е определил, че статията е резултат от работата на ИИ в 75%. Както виждаме, разликата между получените резултати е колосална.

Тази ситуация ясно показва, че всеки инструмент за проверка на текстове има свои собствени алгоритми, критерии и подходи за разпознаване на генерираното съдържание. Липсата на единни стандарти за откриване означава, че съдбата на научната статия може да зависи не от нейното реално качество и оригиналност, а от това, коя програма е избрал конкретният журнал.
Струва ли си да се доверяваме на инструментите за проверка на наличието на ИИ?
Приведените примери и споменатите по-горе недостатъци показват, че съвременните детектори на изкуствен интелект имат съществени ограничения и неточности, които поставят под съмнение тяхната надеждност като единствен критерий за оценка. Те могат да дават непредсказуеми резултати, не винаги отчитат контекста на използване на технологиите и понякога погрешно идентифицират качествено написани академични текстове като създадени от ИИ. Когато един и същ текст получава различни оценки при различни проверки, а опитите да се коригират отбелязаните фрагменти водят до неочаквани резултати, става очевидно, че тези инструменти все още не са достигнали необходимото ниво на точност.
Ето защо е рисковано да се използват като основен или единствен критерий при вземането на решения за публикуване. Дори самите разработчици на тези системи отбелязват, че техните програми не са съвършени и могат да грешат, а резултатът от проверката е само вероятностно предположение за произхода на текста, а не окончателно доказателство.
На първо място, академичната общност трябва да разработи прозрачна политика по отношение на етичното използване на ИИ, да акцентира върху оценката на съдържателната оригиналност, методологията и научния принос на автора. Само такъв подход ще позволи да се запази академичната добродетелност, като същевременно се адаптира към бързото развитие на съвременните технологии.


